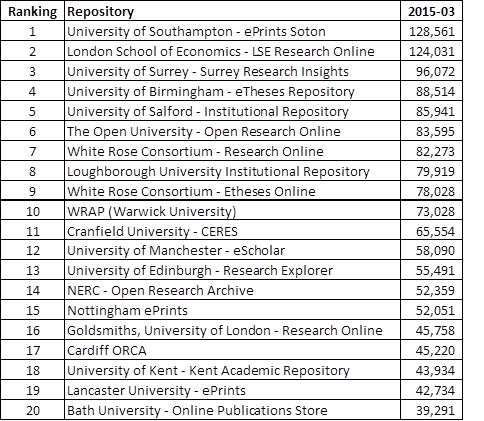
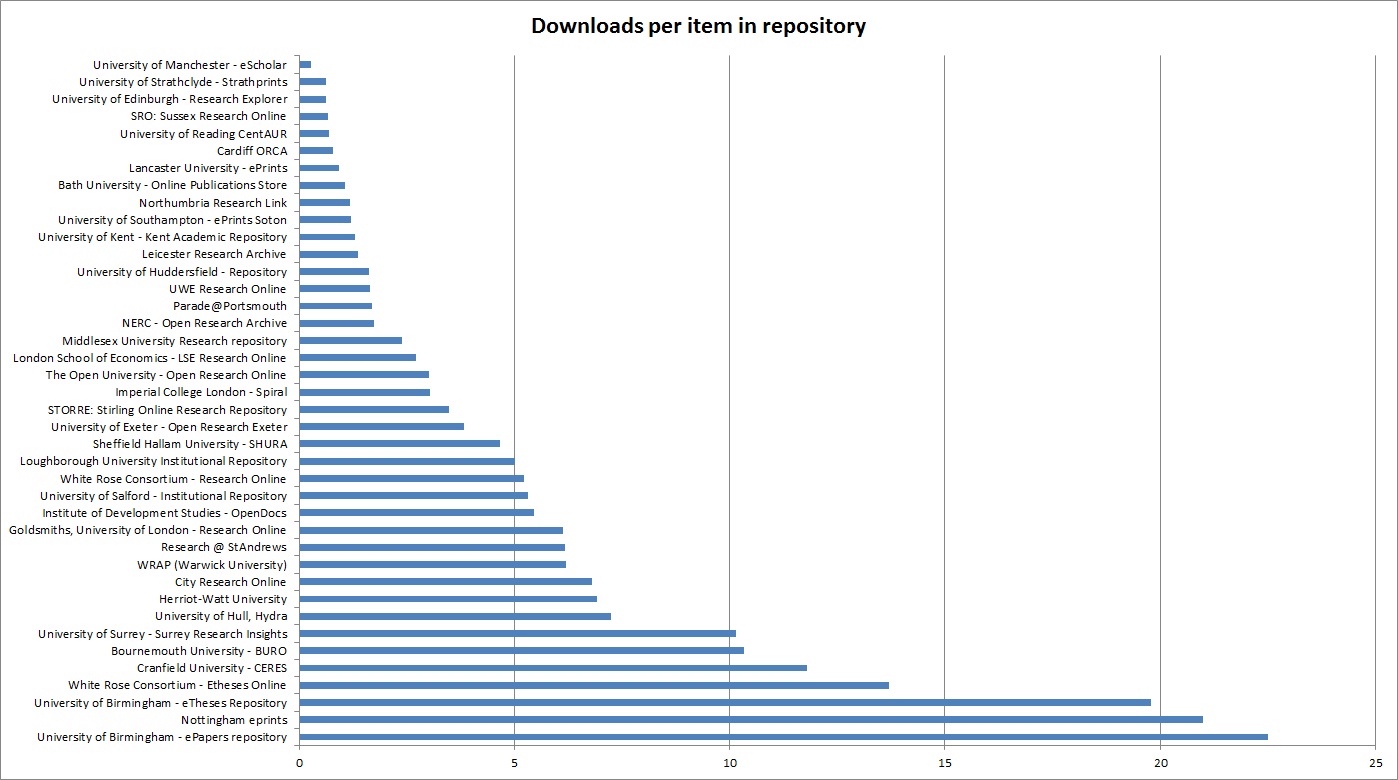
Inspired by Isabel’s “Share and share alike: Top 5 reasons to share your research data” post I’ve come up with my own “Top 5 reasons to use ORO”. As is the custom, in reverse order…
5. Maintain your academic profile.
The ORO author view page is a page that lists all your research publications. Rather than re-list all your publications on your personal webpage or a page on a research networking site – you can use the ORO list.
Additionally, ORO is used to feed the publications page on your OU People Profile. Making sure all your publications are in ORO keeps these pages up to date.
4. Comply with Open Access Policies.
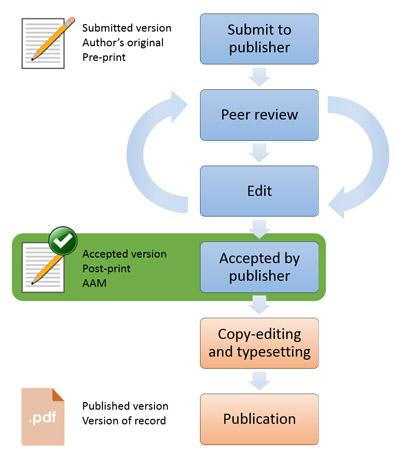
The policies are coming thick and fast! The new OU Open Access Policy and HEFCE Open Access policy for the next REF shift the emphasis from Gold Open Access to Green Open Access.
Both require the deposit of Author Accepted Manuscript versions of journal articles and conference items (with an ISSN) at point of acceptance by the publisher. HEFCEs visual (right) is a nice simple way to see what is required and when.
Making ORO part of you publication workflow means you will be eligible for future REF exercises.
3. Increased citations.
But some of the best reasons to use ORO are that you benefit from it directly
One big benefit is that making your research Open Access means more people read it and more people will cite it. A recent study from Chalmers University of Technology in Sweden has shown that papers self-archived in their Institutional Repository are cited 22% more than articles that hadn’t been self-archived.
2. Increased dissemination
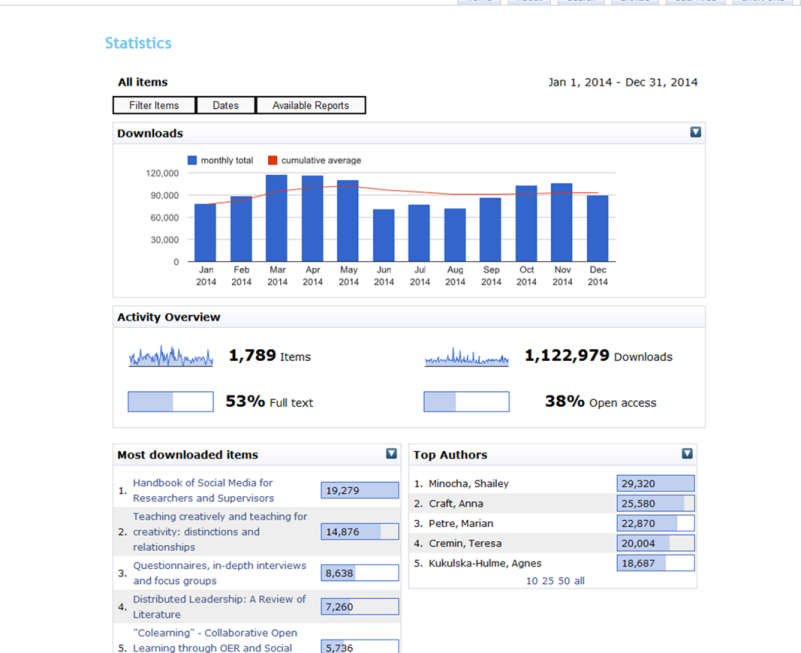
Similarly, ORO has a statistics package that records all the downloads of full text items archived in ORO.
Did you know that in 2014 ORO recorded over 1 million downloads of full text papers from ORO? Some individual papers are downloaded 1,000s of times annually.
You can access your personal download counts from the IRStats2 webpage and then filter by author.
Download counts can be used to aid grant applications, report research dissemination back to funders and can support career progression.
…and top this week…
1.Open Access is a good thing

Using ORO to make research outputs Open Access means that everyone, inside and outside the academy, has access to research publications.
In a 2013 Taylor and Francis survey of T&F Authors 36% disagreed or strongly disagreed that they had access to “most of the articles they need” – remember these are published authors so this is the information gap inside academia.
Reaching a paywall to research outputs for readers outside the academy is the norm and has led to innovations like the Open Access button which identifies publications behind paywalls and attempts to locate Open Access copies. Curiosity by simonas gutautas
But of course using ORO is an intervention in itself; use ORO to remove the paywall.