
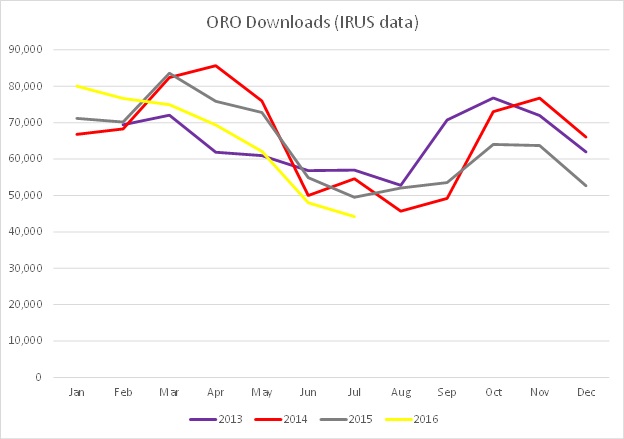
In July 2016 44,215 items were downloaded from ORO this compares to 48,009 in June and 62,084 in May. Downloads (and site visits) decline over the summer months and match the academic year with greater activity during term time and quieter over holiday periods.
The downloads pattern (below) is spiky and based on a dataset from Feb 2013 onwards but it does show a dip over the summer months and at Christmas.
The site visits pattern (below) has a larger data set from Jan 2011 onwards and shows the seasonal variations more consistently.
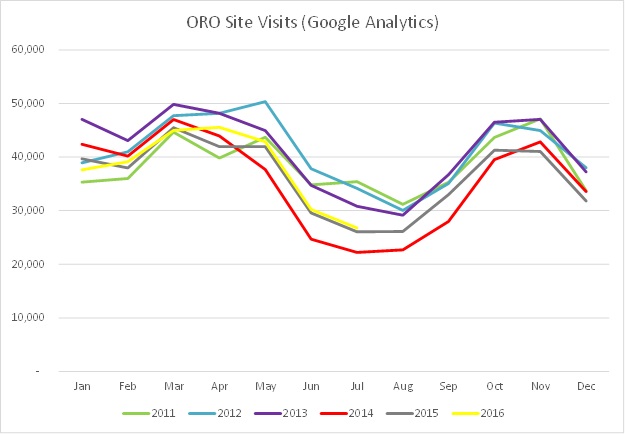
Well, that’s all well and good but it’s not so insightful is it. Maybe not, but there are a couple of other observations we can make when we look at the data in this way.
(1) How come there are more downloads per month than site visits? Surely you need to visit the site before you can download something? Well most of the downloads come straight from Google or Google Scholar where you can download the full text directly from the search results page. So these downloads aren’t counted as site visits in themselves (by Google Analytics).
(2) Site visits peaked in 2012/13, dropped in 2014 and have steadily consolidated since then. I was alarmed with the drop in 2014 – some colleagues at other Institutional Repositories thought this was the effect of REF 2014 with high usage leading up to submission in 2013 and then a drop off of usage after submission in 2014. Maybe that’s the case, maybe also it’s the effect of (1) with the repository effectively becoming invisible to users accessing content via Google and Google Scholar.
(3) Why are the download stats so spiky? Well the above counts (IRUS) are the best we have to go on and they are COUNTER compliant. Nevertheless, they don’t represent individual clicks from humans accessing known research content – some downloads are from automated harvesters. These robotic downloads are frequently detected and filtered out of download counts by IRUS but others may not be detected and may be counted until they are detected and filtered out. Moreover, there are genuine research reasons for mass harvesting of repository content for text mining as a research corpus.