
You are here
- Home
- Comment and Debate
- The Underperformance of White Working-Class Students (3)
The Underperformance of White Working-Class Students (3)
Here’s another table:
.png)
Table A: Proportion of pupils at the end of key stage 4 achieving five or more GCSEs at grades A*–C including English and mathematics, by ethnicity and free school meal eligibility (England, state-funded schools (including academies and CTCs), 2012/13, revised data). Source: Department of Education, quoted in the House of Commons Education Committee Report of 2014/15 , p.16
The only thing it indicates unambiguously is that income background has a correlation to performance in GCSE tests: low-income backgrounds (with free-school-meals or FSM eligibility) are more likely to result in indifferent performance in national tests. That is irrespective of ethnicity. Quite possibly, on beholding this table, you found yourself making some subtle distinctions according to ethnicity – such as, for white British and Irish the difference due to income background seems quite large, for Bangladeshi and particularly Chinese rather low, and so on. The table is structured so as to invite you to make those distinctions, and the temptation to respond accordingly is strong. One might begin to wonder about the cultural practices of different ethnic groups: the Chinese tend to work harder, Bangladeshis have high aspirations, white British are more socio-economically stratified, etc. – but, pause. Bearing in mind that this table too has left the context of scales out and put ethnic groups as discrete and similarly comparable, it is best to pause before giving into the tacit invitation. As observed in the previous posting , such distinctions are meaningless without factoring in the levels of diversity within and across ethnic groupings and the weightings of majorities in determining norms of performance. This table – actually the governmental and news reports I have been picking these from generally – offer no equipment to enable contextualising of that sort. The only consistent pattern, consistent enough to supersede (but not obviate) the need for such contextualising, is that income-background bears upon performance in a markedly similar way.
Talking of norms of performance in national testing, we shouldn’t forget that these figures are for state-funded schools and exclude independent schools (euphemism for private, usually fee-charging, usually selective schools). It seems convenient to put them aside: it is no secret that, embarrassingly, their performance indicators for national tests are significantly higher than for state-funded schools (but doesn’t that say something about income-levels and performance?), they are havens of the relatively affluent who can ensure suitable resourcing for their children's education (but are there still distinctions according to income-backgrounds to make there?). Nevertheless, insofar as their students take the same national tests, their performance is part of the norm of performance. And, there are different ethnicities involved in the independent school sector too. Here’s a nice table from the Independent School Council’s 2015 Census, where everyone who is not white British is lumped together as minority ethnic (so, comparable as a large discrete lump):
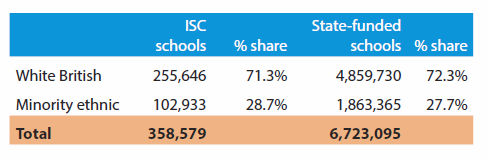
Table B: Ethnicity comparisons for schools in England: Number of pupils and % share (2014); source: ISC Census, p.15.
Non-British students (whose parents live overseas) formed just over 5% of the total number of students in independent schools, with significant numbers from European countries and the USA.
Back to Table A, and other such -- the question that really arises is: why is statistics on ethnicity tracked so thoroughly and pervasively, in relation to every social factor, in governmental reports? What purpose is such tracking meant to serve? I think the answer, from the public-sector statistician’s perspective, is a straightforward one: because it can be, because the data according to ethnicity is already out there ready to be collated in relation to anything. It is not so much the bearing of ethnicity on the social factor in question that motivates statistical tracking, it is the existence of the data on ethnicity that enables all kinds of statistical tracking in relation to all kinds of social factors – and seemingly gives ethnicity-tracking a life of its own.
However, the reason why this data exists, why it started being habitually and pervasively collected and collated, had really to do with a specific social factor – not all conceivable social factors that might become of interest.
The data exists because of anti-discrimination Equal Opportunities legislation and monitoring. With statistical imperatives in view, it is particularly the monitoring that is of interest here. From the Race Relations Act of 1965, 1968, and 1976, and the Sex Discrimination Act 1975 , to the Equality Act 2010 , every step of Equal Opportunities legislation was followed by calls for and, gradually, requirements of monitoring enjoined on employers and public sector institutions (such as schools and universities). Monitoring systems needed to be set up to determine the effectiveness of anti-discrimination legislation, i.e. the adoption of equal opportunities policies within institutions. As far as sex went, statistical monitoring had mainly to consolidate existing data and fine-tune data-gathering practices. From the beginnings of policy-led statistical recording in the late 18th century (or even the 17th, if one goes back to "political arithmetic"), recording sex had been a standard practice. Legislation against racial discrimination brought about a need for setting up systematic and large-scale recording of what is now considered "ethnicity". This need was discussed in the Race Relations Board’s Report of 1966/67 (London, HMSO, 1967), set up after the 1965 Act; it featured prominently in House of Commons debates (Parliamentary papers, 23 October 1974-12 November 1975, Vol. 33, Appendix 8) just before the 1976 Act. It began to be implemented after 1976.
The Commission for Racial Equality set up in 1976 produced a pamphlet, Monitoring an Equal Opportunities Policy: A Guide for Employers (London, 1976), which set out graded levels of “classification by ethnic origins” to be monitored, recommended a principle of self-classifications (individuals declaring which category they belong to), and asserted that data gathering needs to be undertaken regularly across the board and not simply be left to interim audits. The Equal Opportunities Monitoring Form as we know it, the main tool of raw statistical data collection on ethnicity, came to be administered routinely across public sector and other institutions by the end of the 1980s. Gradually columns other than sex and ethnicity were added to it -- on disability, religion, sexual orientation, age -- as Equal Opportunities legislation expanded in range. Such a process of data collection, in fact, proved to be the most manageable aspect of the response called for by legislation: bureaucrats and executives at all levels got down energetically to securing the data (it looked comfortably like an account book exercise). Sarah Neal’s The Making of Equal Opportunities Policies in Universities (SRHE and OU, 1998), based on case studies, found on consulting upper-level managers that: “In many ways, monitoring appears to be almost a ‘red herring’ […]. In other words, to be able to point to an extensive monitoring programme bolsters apparent commitment to equal opportunities policies, while monitoring actually represents little more than a passive and technicist procedure” (p83). Subsequent legislation, especially the 2010 Equality Act, took care of that to some extent and enjoined more active demonstrations of commitment from employers. By this time, every policy and regulatory move had come to be informed by an enormous infrastructure for gathering and processing data on ethnicity via Equal Opportunities monitoring.
If the data is there it should be used wherever possible, irrespective of the purpose for which it was initially gathered. It may well be relevant where it is least expected to be. This has been an unshakeable dictum from the beginning of systematising statistical tabulations: at its foundational moment as an applied method, John Graunt’s various inferences made by tabulating data from the Bills of Mortality in the late 17th century (1662-1676) had fundamentally made that point. So, all that data on ethnicity that has been collected and tabulated through a robust methodology since the 1980s cannot but be used by UK statisticians wherever they can be. It is not for statisticians to do otherwise; it is for readers to pause on carefully analysing the assumptions and implications of the tabulations. That’s particularly so where the readers also determine governmental policy and mould public attitudes.
Recalling the reasons for the availability and widespread use of data on ethnicity raises an interesting question in this context: what bearing does disquiet about the underperformance of white working-class students have on Equal Opportunities principles – principles which seemingly underpin liberal policy and governance so firmly now?
On that question, the next posting.
Suman Gupta
May 2016


Explore

Undergraduate
Postgraduate
Policy
-
Follow us on Social media
-



