
 The latest instalment of my series on best practice in ORDO looks at sharing videos.
The latest instalment of my series on best practice in ORDO looks at sharing videos.
In late 2017, we were approached by Dr Erica Borgstrom from the faculty of Wellbeing, Education and Language Studies. Erica’s research focuses on death and dying, with a particular focus on end of life care. Over the course of the previous year she had been running a series of seminars on death and dying, all of which had been recorded and posted on an OU hosted website. Erica was concerned that the website would not be supported for much longer and that the videos were of high interest and needed to be made available to the public on another platform.This is where ORDO comes in – by putting the videos of the seminars on ORDO, they were given the security and credibility of being hosted on an OU platform, and we were able to guarantee that they would be maintained for a minimum of 10 years. Adding the videos to ORDO gave each one a DOI, enabling Erica and the seminar presenters to cite them at conferences or in papers and ensuring that they are recognised as valid research outputs. ORDO allows in-browser viewing of most audiovisual file types which means that the videos don’t need to be downloaded to be watched. We were also able to add metadata to the records to enable discoverability, and upload extra background documents alongside the videos to add context.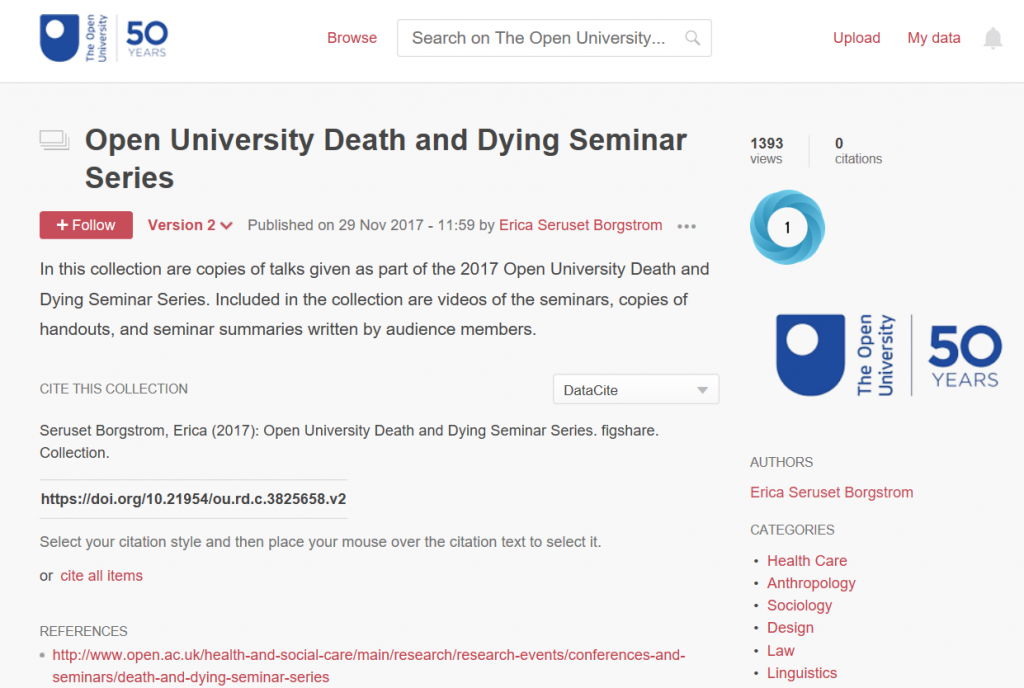 Finally, we grouped all the videos together into one collection, giving the entire seminar series a DOI and ensuring that they are seen as a complete body of work.
Finally, we grouped all the videos together into one collection, giving the entire seminar series a DOI and ensuring that they are seen as a complete body of work.
Seruset Borgstrom, Erica (2017): Open University Death and Dying Seminar Series. figshare. Collection. https://doi.org/10.21954/ou.rd.c.3825658.v2
Since the seminar series was uploaded to ORDO in January 2018, the videos have consistently featured in our top ten most viewed items. They have been viewed almost 7,500 times and downloaded 571 times.
A brief note from Erica:
I found working with ORDO and the library staff very helpful and exciting. Uploading and storing the videos in this way make them easy to share with a much wider audience and helps us fulfil our mission as an open, and accessible, university. The seminar speakers have also appreciated the professional platform to recognise their talk as a research output.





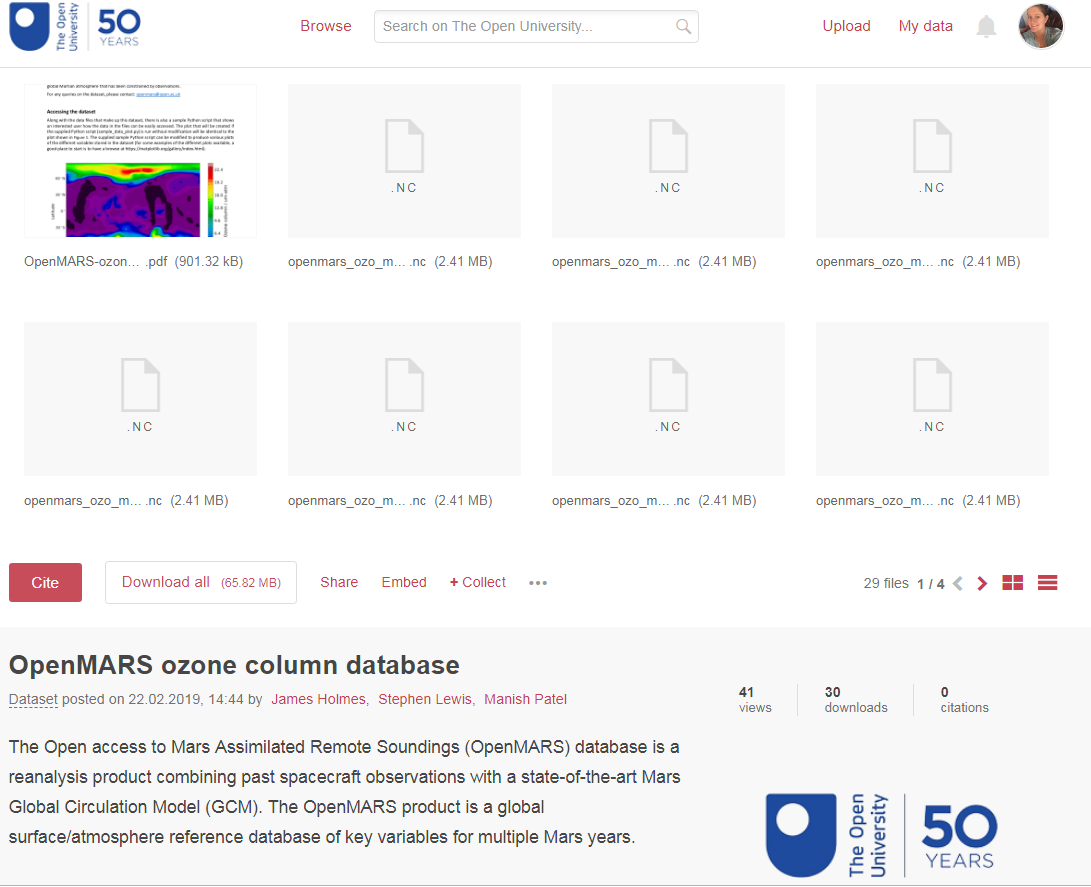 There are four datasets which are published individually and also grouped together as a collection. The most impressive thing about these is the documentation accompanying these datasets, which is excellent:
There are four datasets which are published individually and also grouped together as a collection. The most impressive thing about these is the documentation accompanying these datasets, which is excellent: