

Ifaz Ahmed, Nuffield Research Placement Student
Working with Nuffield Research Placement Scheme co-ordinators, Dr Pallavi Anand promoted the scheme across STEM to host nine ‘A’ level students during the summer of 2022. Students were placed in various academic schools in the STEM Faculty.
One of the placement students (Ifaz Ahmed) and his host (Dr Dhouha Kbaier), based in the School of Computing and Communication, have captured their experiences of the summer placement in this post.
Ifaz’s perspective
My placement was evaluating the application of data science and machine learning in different research areas (e.g. identifying transaction fraud in finance, or identifying patterns in lifestyle or medical records in patients with a specific disease or illness), and exploring it through Python.
I critically assessed the risks and mitigation methods of different AI technologies such as deepfakes, and different ways of minimising the risks of AI development; for example researching The Institute for Ethical AI & Machine Learning.
Beyond AI safety and usage, I learnt data pre-processing, imputation, analysis, and visualisation. For example, relating to data science applications in business, I pre-processed Mercedes Benz CL/SL sales datasets and dealt with missing values, solved through dropping values with any null values within any relevant columns. This could be further improved upon through data imputation. Beyond this, aggregates were calculated and visualised identifying the standard deviation of both CL and SL sales.
Machine Learning models can be used in different ways (i.e. prescriptive, predictive modelling) and I learnt how to perform a linear regression of any number of variables to predict house prices based on a given processed dataset.
Within the project, I selected the independent variable “Distance to the nearest station” and plotted it against the respective house price column. This revealed a correlation in the dataset, so I was able to use scikit-learn to create a linear regression model. However, this only used a single independent variable so I sought to use more.
I enjoyed using libraries to create and visualise a Machine Learning model based on three independent variables. I chose the independent variables “House age”, “Distance to the nearest station”, and “Number of nearby convenience stores” to predict the house price. Upon fitting a linear regression model to the dataset, I visualised the linear regression line through a 4D matplotlib diagram (Figure 1).
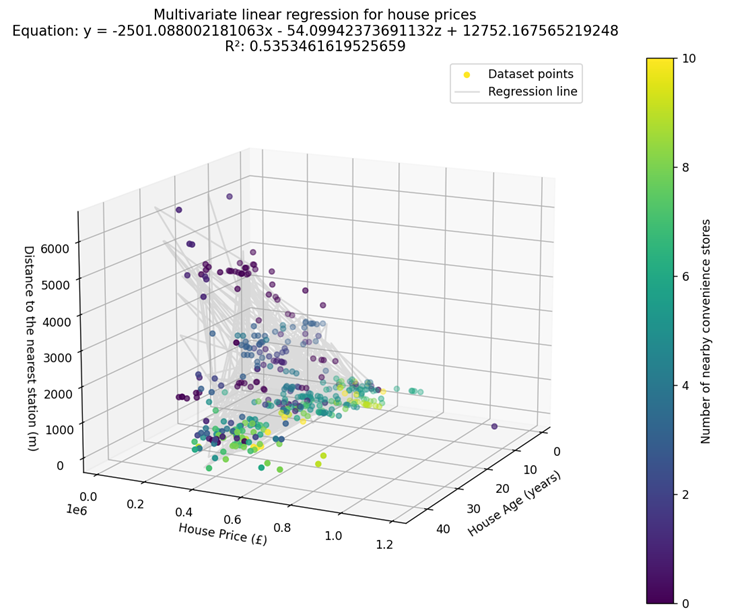
Figure 1: A linear regression line through a 4D matplotlib diagram.
I loved researching different problems and methodologies pertaining to data science. One such problem is identifying the best way to handle faulty or slightly flawed datasets, such as the COVID vaccination statistics dataset wherein country names were nonuniform. This posed a problem of causing inaccuracies and missing data values in visualisations or anything based on this. This was overcome by using ISO codes instead, which were uniform and consistent throughout.
The placement has encouraged me to undergo further research in higher-level fields, such as neural networks. This is due to the limitations of basic regression, where neural networks will be able to fill in their short-comings. One such application I’m currently working on is using backpropagation in a Convolutional Neural Network to classify images of flowers to a large range of species. The placement has allowed me to understand how to correctly handle data including imperfect data.
My placement was very flexible and paced excellently, with constant yet reasonable expectations and deadlines to maximise my productivity. It has introduced me to conducting research and constructing reports, as well as a scientific poster. I was able to make rapid progress over the course of my placement through my mentor who was able to explain any question I had and consistently gave me high-quality feedback.
Overall, I’ve gained an amazing skill set; for example usage of numpy/pandas, data visualisation through matploblib and seaborn, and scikit-learn models. These new skills will prepare me for university and my career.
Dr Dhouha Kbaier’s perspective

Dr Dhouha Kbaier
(Senior Lecturer in Computing and Communication, STEM)
It was a pleasure to supervise Ifaz who was committed, engaged, interested, and eager to learn new things.
During his placement, Ifaz was working on Python for data science. He first worked on research questions regarding data science, machine learning and artificial intelligence. Then, he used Python to explore different datasets.
Ifaz analysed the data, and applied advanced tools and techniques. As soon as I shared useful resources with Ifaz, he was able to learn from them very quickly. Additionally, he was independent in the development of his academic skills and the writing of his report.
I provided feedback and guidance for both the report and poster. Ifaz’s report is excellent, aligned with higher education academic reports, and his poster follows the ‘dos and don’ts’ I suggested to him.
Ifaz and my other students were a pleasure to work with, and I look forward to working with other students next year.