Category → telstar
Innovations with reference management software
When looking at dissemination opportunities for Telstar we wondered if there was a community of people using bibliographic management software like RefWorks, EndNote, Zotero, Connotea, CiteULike, and more recently Mendeley, that we could target. However, when we went looking, there didn’t seem to be any particular focus point for this. So we thought that something Telstar could do as part of it’s own dissemination activity was hold an event looking at how these different packages were used, perhaps especially where they are being used in innovative or interesting ways (of which we hope Telstar is an example).
We are currently looking at a free, one day event in mid-January, aiming for about 50 people attending, with a variety presentations or other sessions.Would you be interested in attending such an event. If so, is there anything particular you’d like to see on the agenda. Some ideas that I’ve had is:
- The work of the Telstar project (of course)
- Library usage of RefWorks – reading lists, recent library acquisitions lists
- Referencing and Linked Data/Semantic web
- Something about Mendeley?
- Examples of using Zotero in innovative ways? (exploiting shared libraries/RSS?)
As we firm up plans we will put up more information, but in the mean time please leave comments indicating whether you’d be interesting in attending, what you’d like to see presented or talked about, and if you have any other suggestions or questions. Also, if you’d be interested in presenting – let me know!
Linking strategies
I’ve written a couple of posts on linking from references to resources, and particularly on how we are planning to use OpenURLs to provide persistent links to web pages, but I’ve not yet described our overall approach to linking.
Through discussion with a variety of groups at the OU, we settled on the following principles:
- Links should ideally take the user straight to the full-text resource, with no intervening pages
- Avoid manual creation of links whenever possible without having a negative impact on the student experience
- We should know what resources and links are being used and where
- When moving references between different environments, any links provided with the references should continue to make sense
- Mechanisms to provide and administer links from references to resources should be as simple as possible
There is a blurring of lines between different types of material online, but we can probably regard the types of resource we want to link to as:
- E-journal articles
- E-book chapters
- E-journals (title level)
- E-books (title level)
- Databases
- Web resources (pages, videos, podcasts, pdfs)
This is probably a very ‘library’ perspective on how materials are divided up – ultimately if they are on the web you could probably regard them all as just ‘web resources’, but in terms of linking it is useful (to me anyway) to think of these categories.
The major decision we have made is to push all links via our OpenURL link resolver – SFX. There are a few reasons for this:
- We can create OpenURLs from reference metadata – which means that we can create a link to an article without an explicit URL in the reference. While the reliability of this is not 100% (we can’t guarantee that we can create a link), it’s pretty good for journal articles
- We can collect statistics in a central place – SFX can report on each link that is routed through it
- It is a single consistent approach for linking – we don’t have to code different behaviours into the links within the VLE to handle different scenarios or types of resource
- Using OpenURLs and SFX doesn’t commit us to any particular method of linking to resources, it just means we can use the existing SFX framework to manipulate links when we want to
If the OpenURL contains a URL in the rft_id field, we would use this to link to the resource – as I’ve previously described. Although this is mainly intended for the category I describe about as ‘web resources’ it can apply to any of the resources – essentially if the reference creator has gone to the bother of entering a URL into the reference, that’s where we will send the link.
The current preferred method for linking to e-journal articles at the Open University is to use a DOI and the DOI resolution service at http://dx.doi.org. So, our second rule is that if SFX receives a DOI in the OpenURL, then it simply pushes the user to http://dx.doi.org to resolve the DOI by that route. Although it is usually e-journal articles that have DOIs, other types of resources – books, chapters, conference proceedings, etc. can have DOIs, and this would work for any reference that includes a DOI.
If the OpenURL does not contain a URL or a DOI, then we use the native capabilities of SFX to try to provide a link to the full-text. If SFX can’t identify a full-text source, then the user gets an explanation.
The logic is illustrated here:
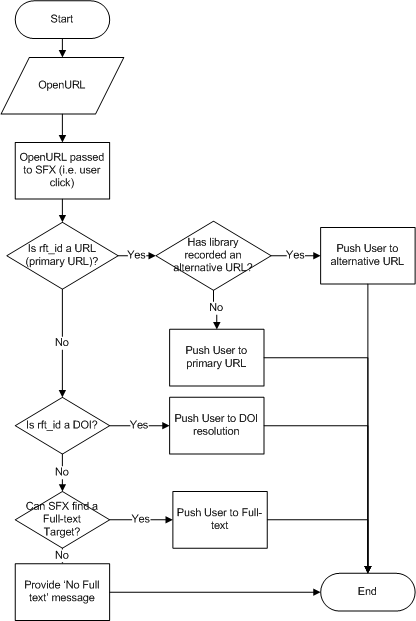
In order that the very last scenario doesn’t happen (or happens as rarely as possible), we have decided that we will only provide links from references in the VLE if one of the following is true:
- There is a URL in the original reference
- There is a DOI in the original reference
- The original reference is for a journal or journal article
The first two are obvious, and the third is because we think that it is highly likely that any cited journal/journal article will have a full-text version available to students at the Open University. We also include an ability for the reference creator to override this logic and suppress any links in the VLE on a reference-by-reference basis.
Hopefully this is in line with our principles:
- Links should ideally take the user straight to the full-text resource, with no intervening pages
- The URL or DOI should do this reliably, SFX does this for some, but not all, e-journal services (this is usually dependent on the type of inbound link supported by different e-journal platforms
- Avoid manual creation of links whenever possible without having a negative impact on the student experience
- It is possible to enter just basic reference metadata for e-journal articles and for a link to be created automatically. If you have a DOI that’s even better – but you don’t need to enter the resolution URL – just the plain DOI.
- We should know what resources and links are being used and where
- SFX can report on what links are coming from which course in the VLE
- When moving references between different environments, any links provided with the references should continue to make sense
- The approach we are taking should allow us to record references without any Open University specific information embedded into the reference – so if you export the reference to a different environment or context, it continues to make sense
- Mechanisms to provide and administer links from references to resources should be as simple as possible
- Hopefully by acheiving all of the above, we have also acheived this one…
TELSTAR Demonstrations
TELSTAR is working on three main types of integration between the RefWorks reference management software and technology enhanced learning at the Open University. We are now at a point where we have enough functionality to do some demonstrations of what has been developed.In this post there are three 5 minute screencasts which demonstrate the range of functionality that has been developed. I’m afraid the sound quality isn’t quite as good as I’d like, but hopefully this won’t detract from the demonstration. Please feel free to post comments and questions below.
Integration with Course authoring tools
Integration between RefWorks references and Moodle course Resources
RefWorks Account integrated into a Moodle module
Mobile Libraries
On Thursday I blogged the presentation of the Erewhon project based at Oxford University. I promised that I would follow up with a post on how I thought the project was relevant to the work TELSTAR is doing – so here goes.
One of the services that Erewhon is looking at delivering is something like being able to answer the question ‘where is the nearest (Oxford University) library to my current location where I can get this book/journal/other?’. This relates very much to questions that we’ve been discussing for TELSTAR and I’ve already blogged about – given a reference, what is the route of access to the resource being referenced.
The TELSTAR project is focussing on answering that question with respect to the online resources offered by the Open University via the Library service. This is clearly a great starting point, and as we deliver more and more resources electronically, it becomes more likely that for any particular resource we can deliver it electronically.
However, what about those things that aren’t delivered as part of the course materials, and we can’t provide electronically via the library? This is where we want to start being able to respond more to a particular users ‘context’ – and where they are is a good place to start. It would be great to be able to answer the question “where is the nearest library to me that I can get this book?”or perhaps more generically “where is the nearest library to me that I can access this resource?”. The latter question is important because you may be able to access electronic resources by going into a library – often licenses enable libraries to offer ‘walk-in’ access to electronic resources to visitors.
There are some services that already try to answer these questions. Worldcat can answer this question for libraries that have their records in Worldcat. Talis have setup a directory of libraries, including location details, which might be used to generate this type of service (as Chris Keene demonstrated at the Mashed Library 2008 event). If we could combine this type of service with the type of Geo-location work Erewhon is doing then we could start to answer these questions. It’s a shame that the SCONUL Access scheme database doesn’t seem to have an API to get details of local libraries.
However, this is focussing on the physical collections – I’m also interested in the electronic. Within TELSTAR we are pushing all our links via our SFX OpenURL resolver – this allows us to work out the most appropriate route of access (termed the ‘appropriate copy’) to an electronic resource. The OpenURL Router could point the way for this type of service – this service allows you to push OpenURLs to a centralised service, which then tries to route the OpenURL to your ‘local’ resolver. I believe it can do this either based on IP range the request is coming from, or via the specification of a parameter which is linked to concepts of Federated Access Management.
Perhaps with some further work, this could use Geolocation information with ‘nearest library with resolver’ information to push the OpenURL to the relevant resolver, and so offer walk-in access. Potentially this could be combined with information about printed collections if it was supported by the local link resolver, and so you could actually answer both ‘do you have this in print’ and ‘do you have this electronically’ in a single query.
Of course one of the problems is that the user is actually in multiple ‘contexts’ at one time. That is to say, if I’m sitting in one of the Oxford libraries, and I’m a student at the Open University, I have access to all of the Oxford library physical collection, the electronic resources they offer walk-in access to, and all the Open University’s electronic resources. I may even have access to other sets of resources via membership of another library or organisation completely separately. In an ideal world, what the user gets access to is informed by bringing together information from all these contexts, and delivering the resource to the user by whatever route is available.
This is clearly complicated – I sometimes wonder if the solution is for users to have their own OpenURL resolver that can draw on all the information relevant to them, as they are probably the only person who really understands their full context. This seems a rather unlikely scenario to be honest, although this recent blog post on e-books made me wonder if there was a market for an individual resolvers.
Routes of Dissemination
This blog is obviously one way in which we are trying to disseminate the work of the TELSTAR project. The recent presentation at ALT-C and resulting YouTube video of the presentation were other aspects of our dissemination work. I’m now looking at what the next steps should be.
Traditionally a JISC funded project like TELSTAR might produce some printed publicity materials, present at various conferences, maybe publish an article or two, and possibly have a blog or similar channel for dissemination. Of course, this would be alongside the formal written outputs of the project.
All of these seem quite reasonable approaches to disseminating project outcomes. However, with TELSTAR I perceive some particular challenges. Firstly, the short time the project has to run means that it is difficult to find conferences that are accepting papers and happen before the end of the project. Secondly, the potential audience for TELSTAR is broad (it may not be that unusual in this), meaning it is difficult to identify channels that reach all of the possible interested parties. Earlier this year Lawrie Phipps, who is the JISC Programme Manager for the Institutional Innovation strand that TELSTAR is funded under posted some thoughts about dissemination for educational technology projects.
Some brief, but (I think) interesting statistics:
- Audience at TELSTAR ALT-C presentation: 20-30 people (that’s a guess on my part)
- Views of YouTube video (after 5 days): 301 viewings (and they weren’t all me)
- This blog (since 23/8/09): 182 unique visitors, 294 visits, 468 page views
- Discussion generated by single post to code4lib mailing list: 58 emails
So, I thought I’d ask for suggestions – please leave comments below – how should we disseminate the work of the project? What works for you? Do you have any examples of excellent dissemination of project outcomes? What would you like to know?
ALT-C – the presentation
I was lucky enough to attend the ALT-C conference last week (you can read my general reflections on the ALT-C if you want), and even luckier (?) to have the chance to present on the TELSTAR project. If you weren’t able to make the live event (or if you were, but want more) – here it is:
It’s about 10 minutes long, and endeavours to outline the problems we are tackling, and the work we are doing.
Managing link persistence with OpenURLs
Statement of problem
Web resources can change location over time, or the route of access for users belonging to a specific institution can change with the same outcome, i.e. broken links. This is undesirable when providing links within teaching material where it is impractical to review and republish the material on a regular basis.
The current approach at the Open University is to create ‘managed’ links which are used in teaching material and environments instead of the primary link for a resource. These managed links are managed by two systems:
- For free web resources managed links are provided by ROUTES
- For subscribed web resources (e.g. databases) managed links are provided by a locally developed system
An example is that if we wish to include a link to the BBC homepage within the VLE we would not use the Primary URL:
but instead use the ROUTES created ‘managed’ URL:
Although this practice solves the problem of persistence over time (if the primary URL for the web resource changes, we can update the ROUTES or local system without having to update the course material), it creates several new problems:
- To provide a link to any web resource you have to know a special link, which you have to ask for from the library
- The ‘managed’ URLs do not make sense outside the context of the OU, meaning that if a student copies a reference to a resource, including the link, these references are not really appropriate for use except within the OU environment
- The library has to ‘manage’ URLs for all referenced resources, no matter whether the Primary URL is correct or not
Business Requirements
In order to avoid these issues we need a solution which:
- Preserves the Primary URL in the original reference
- Does not require the entry of a special ‘managed’ URL by course authors or others involved with the authoring and editorial process
- Does not require management of Primary URLs which are valid
Proposed Solution
The proposed solution is that we should use OpenURL to provide links to resources wherever possible. For bibliographic formats – journals, journal articles, books (whether in print or electronic) the expression of these in OpenURL is well documented, and the translation of the OpenURLs generated by link resolvers is well understood.
However, when providing links to a web resource, the use of OpenURL is novel. What it will allow us to do is to take a Primary URL, check whether there is a Managed URL for it and direct the user to the Primary or Managed URL depending on what is available.
The flow would be as follows (using the OU OpenURL resolver, which is an SFX implementation):
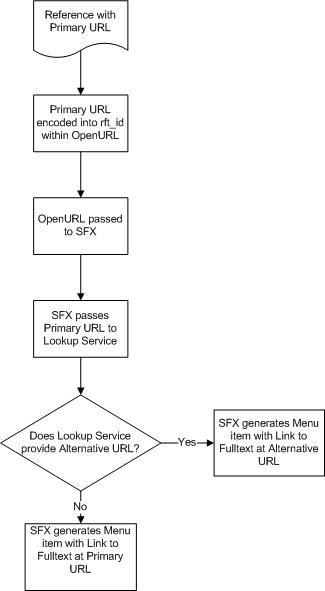
Boxing Clever
About 10 days ago Tony Hirst (@psychemedia) posted a new mashup on the Ouseful blog called DeliTV. The work was prompted by his use of video clips as part of the T151 Digital worlds course at the Open University. In his original blog post Tony describes how he wanted
– a browser based or multiplatform delivery interface that would allows users to watch video compilations on a TV/large screen in lean back mode;
– a way of curating content and generating hierarchical playlists in which a course could have a set of topics, and each topic could contain one or more videos or video playlists. Ideally, playlists should be able to contain other playlists.
What Tony hit on was using the Delicious bookmarking service to create lists of videos (by use of tagging), and the open source Boxee software, which brings together media viewing and aspects of social networking. Tony built some Yahoo Pipe work to take an RSS feed from Delicious and gave you a feed of videos that Boxee could consume, and from there give you a video playlist.
It is this type of use of resources within Open University courses that the Telstar project is concerned with, so I was interested to see whether we could do a similar thing with the platforms we are using for the project – specifically the RefWorks reference management software. I’m glad to say, the answer is ‘yes’.
The key things that makes this possible is the fact you can share items from RefWorks using a function called ‘RefShare’. This allows you to publish a set of resources in your RefWorks account on the web, and optionally include an RSS feed. I was then easily able to copy Tony’s Yahoo Pipe and modify it slightly to make it work with the RSS feed provided by RefShare – and at the Boxee end the functionality is exactly the same, because that deals with the output from the Yahoo Pipe in exactly the same way – one of the beauties of using RSS to push information around the web.
A couple of questions you might have are:
- How exactly do you do this?
- Why use RefWorks/RefShare instead of Delicious
I’ll tackle the second question first. There are several reasons the Telstar project is looking at RefWorks as a basis for delivering references and resources into a teaching environment, but perhaps the major one is that RefWorks is designed to allow you to output references in a wide variety of referencing and citation styles. This is something that is both required when writing Open University course material, and something we require of students when they submit work for assessment – but it can be a fiddly and time consuming process. Using RefWorks you can output all the references you’ve used in the correct citation format – hopefully all the hardwork is done for you behind the scenes. Simple bookmarking services like Delicious lack this functionality, and in general don’t store enough information to deliver full academic references.
We are also developing integrations between the Moodle VLE used by the Open University and RefWorks, which might confersome additional benefits to using RefWorks – the ability to import references from RefWorks into the Open University VLE (Moodle), or subscribe to a RefShare RSS – so if you built the video playlist in RefWorks you could share into the VLE as well. Also for all items in RefWorks, it is a one-click process for students to take a copy of the reference into their own RefWorks account.
Obviously Delicious has some real advantages as well – it is very easy to use, bookmarking and tagging extremely simple, ‘sharing’ is default rather than a decision, and it has a ecosystem of users/developers built up around it. I think particularly the simplicity of bookmarking, tagging and sharing make it more ‘lightweight’ than RefWorks – and I can see that as a big selling point for those building lists of resources – it’s something I’m thinking about a lot as part of the project – how to get resources into RefWorks.
Anyway, that’s the why, what about the how?
First you’ll need a RefWorks account of course. You’ll need to belong to a subscribing institution to do this, so if you belong to a University, ask your library. Specifically if you are at the Open University, have a look at the details at http://library.open.ac.uk/research/bibliomgt/index.cfm#refworks (I’ll be the first to admit this is a bit fiddly, but you only have to do it once!)
Once you’ve got your account/logged on, you will need to create a folder (RefWorks doesn’t use ‘tagging’ but rather organises references into folders – but as a single reference can belong to many folders, it works out as basically the same thing). So find the ‘Folders’ menu and select ‘Create New Folder’:

Enter a name for your folder
Click OK. Then you need to Share the folder – go to the ‘Share Folders’ option on the Folders menu:
You should see a list of all your folders with the option to Share them – click the ‘Share Folder’ option:
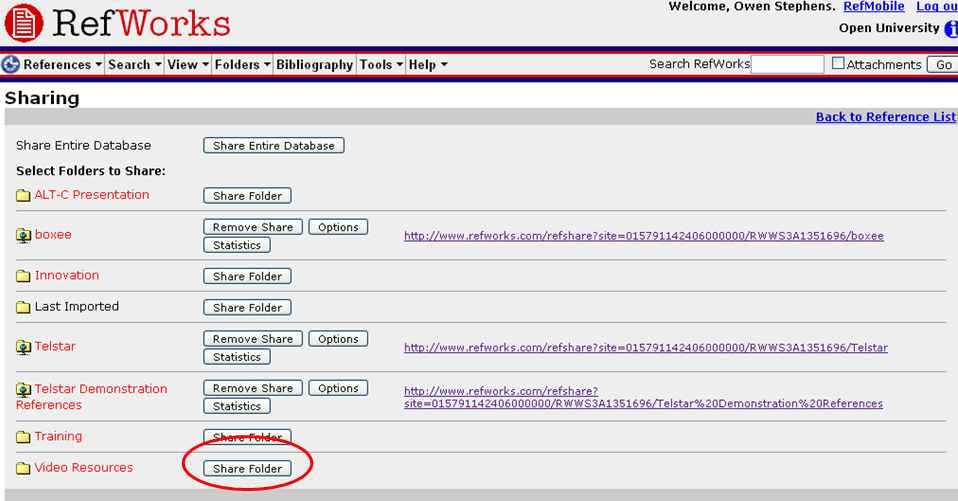
You will then see the Shared Folders options – you need to set the ‘Create RSS Feed’ option – you can decide how many items you display in the RSS feed up to 50 (there are some ways around this limitation if necessary, but I’m not going to go into it now). You also need to give it a Title (otherwise it won’t let you create the RSS Feed).
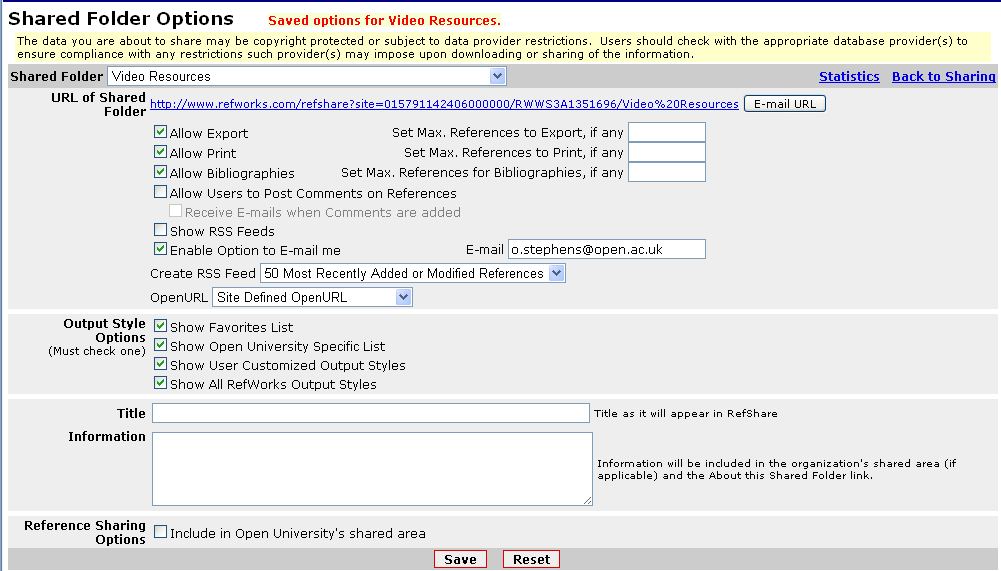
On the option page, you can see a link for the Shared Folder – in this case:
http://www.refworks.com/refshare?site=015791142406000000/RWWS3A1351696/Video%20Resources
You can either visit this page, and then follow the link to the RSS feed, you you can simply add ‘&rss’ to the end of the URL:
http://www.refworks.com/refshare?site=015791142406000000/RWWS3A1351696/Video%20Resources&rss
OK, now you are ready to start adding resources to the folder. You can do this by hand, but I’d suggest using the RefGrab-it bookmarklet/browser plugin – details are at http://www.refworks.com/Refworks/help/Refworks.htm#Using_RefGrab-It_to_Capture_Web_Page_Data.htm. I use the bookmarklet with Chrome, and it works well.
Then browse to the page you want to bookmark. Now, I haven’t tested all of these, but in theory as I’m using the same Pipes code as Tony, his list of what you can bookmark holds true:
At the current time, you can bookmark:
- a particular Youtube video
- (http://www.youtube.com/watch?v=YC8Kk9nEM0Y);
- a Youtube Playlist
- (http://www.youtube.com/view_play_list?p=11DBE3516825CD0F);
- recently uploaded videos to a particular user’s Youtube channel
- (http://www.youtube.com/user/bisgovuk);
- programmes listed in a BBC iPlayer category feed
- (e.g. http://www.bbc.co.uk/programmes/genres/drama/thriller);
- a Deli TV playlist
- (http://delicious.com/psychemedia/t151boxeetest);
- an MP3 file
- (e.g. http://www.downes.ca/files/audio/downeswiley4.mp3);
- a “podcast” playlist
- (http://delicious.com/psychemedia/wileydownes+opened09).
If any of these don’t work, you can let me know and I’ll have a look.
When you have browsed to a page, hit the RefGrab-it Bookmarklet (or plugin) and you’ll get the option to save it. The plugins are a bit more powerful as you might expect. If you use the bookmarklet, it will look something like this:
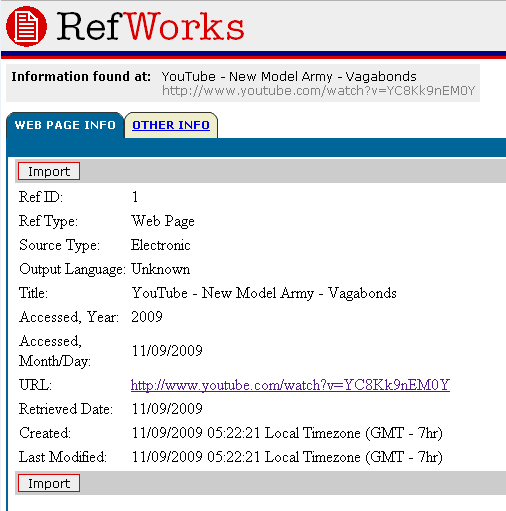
You can then Import it. You’ll get this screen:
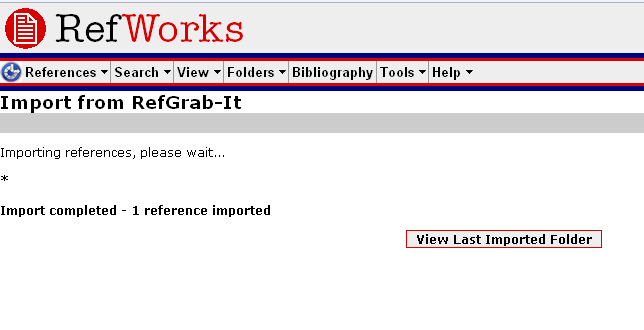
If you then click ‘View Last Imported Folder’, you can put the Reference immediately into your shared folder:
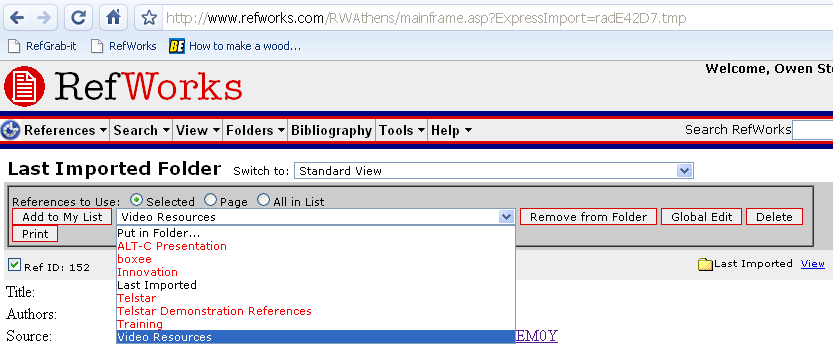
(remember to check the box next to the Reference – a green tick to the left of the Ref ID)
Now you need to get the Pipe feed. Go to the Pipe I’ve created at http://pipes.yahoo.com/pipes/pipe.info?_id=f78732dea457b2e7c4a6415abf7c14c3 and enter the URL for your RefShare RSS feed (remember the RSS feed, not just the RefShare folder URL). Run the pipe, and click on ‘Get as RSS’ – this will give you the URL you need to feed into Boxee – and now we are back into Tony’s workflow – see his instructions for adding a feed to Boxee.
Hopefully that’s enough to get you going. When I can find some time I’m going to look at the Pipe again, but for now treat it as testing only, and it may break.
Double standards
My last post considered the issues of referencing a web resource. In this post I’m going to start bringing in other types of resource that you might reference – books, journals, articles, etc. – but I’m going to come from a slightly different direction, because I’ve started to come to the conclusion that there is a fundamental difference between referencing online and offline resources, and this is worth some consideration.
The difference that I percieve is the difference between a ‘reference’ and a ‘route of access’. A traditional reference to a printed book (or indeed, any offline resource) might look something like this:
Lipson, C. (2006) Cite right, Chicago : University of Chicago Press, c2006.
Whereas a reference to an e-book looks like:
Bronte, C. (1998) Jane Eyre, Project Gutenberg, [Online] Available from: http://www.gutenberg.org/files/1260/1260-h/1260-h.htm (Accessed 27 August 2009)
What’s the difference? The latter not only includes the information necessary to identify the resource, but also a route of access to the resource (by providing the URL).
[To digress for a moment, there may be some question of whether it is necessary to include a URL in the reference, or a URI – the difference being that a URI only has to identify a resource, not provide a location – as opposed to a URL which:
“refers to the subset of URIs that, in addition to identifying a resource, provide a means of locating the resource by describing its primary access mechanism (e.g., its network “location”).” (http://labs.apache.org/webarch/uri/rfc/rfc3986.html#URLvsURN)
I know this seems counter-intuitive to those of us who type URLs into our browser everyday and expect to get a webpage back, but some things that look like URLs don’t actually resolve to anything when put in a browser, and they can still count as URIs.]
Anyway, when citing a webpage clearly there is a reason to include the URL – it is probably the only practical way of identifying the webpage in a way that someone else could reliably find it. But what about other references – such as e-books? The following is a valid e-book reference:
Willie, Sarah Susannah (2003) Acting black: college, identity and the performance of race, Taylor & Francis e-book collection, [Online] Available from: http://library.open.ac.uk/linking/index.php?id=311027 (Accessed 10 April 2006)
This contains the information to identify the book, and also the route of access. Not only that, but for most of you out there (those not a member of staff or a student with the Open University) this link almost certainly won’t give you access to the item. It seems to me that this is analagous to me writing the equivalent print reference:
Willie, Sarah Susannah (2003) Acting black: college, identity and the performance of race, New York, Routledge Available from: 378.1981 WIL Main Library, Level 4, University of Durham Libraries (Accessed 10 April 2006)
It is just as true, and just as useless to most readers. The difference being that the latter is not accepted practice for print publications.
Further to this, you note that this item is available both as an e-book, and as a printed volume. Would it matter which the reader went to – almost certainly not. This seems analogous to a reference differentiating between hardback and softback printed editions (which they don’t) – although I can see there may be some issues with pagination should you reference a specific page.
So what is the solution? My own opinion is that the only sensible way of handling links related to this type of material is to use OpenURLs and ‘Link Resolver’ software to allow the linking of reference to resources. By doing this, you allow the question of ‘where can I access this’ to be answered individually for each user, rather than suggest there is a single answer for an e-book, an e-journal or an e-article. By I’d be interested to here what others think?
The missing link
Over the past few weeks I’ve been thinking a lot about how we should provide links from a reference to a resource. (There is perhaps another question of whether providing a link from a reference to a resource is desirable in all cases – any comments on this welcome, but for the purposes of the current discussion I’m going to assume that generally given a reference to a resource that is available online, we should provide a link.)
There are several different scenarios for this depending on the type of resource we are referencing.
Let’s start with something that seems simple – a reference to a website. Typically if you cite and reference a website in a piece of writing, the reference would look something like this (using a modified Harvard style):
JISC Technology Enhanced Learning supporting Students to achieve Academic Rigour (TELSTAR) : JISC, http://www.jisc.ac.uk/whatwedo/programmes/institutionalinnovation/telstar.aspx (Accessed 24 August 2009)
This seems relatively straightforward – you are referencing a website, and you include the URL – what could be simpler?
However, if we used this in the context of an Open University course, we recommend that when linking to external websites that you do so via what I would term a ‘managed’ link. So, rather than link directly to http://library.open.ac.uk/ you would get this URL added to a database (maintained by the library) which would assign a locally managed URL for use – for example it could be something like http://managedurls.open.ac.uk/123456 (note, this is not a real example).
Why do we do this? URLs are often not as stable as we’d like, and over the lifetime of a course (several years), a resource may move where it is hosted on the web. By directing the link via a ‘managed’ URL, we can update where this redirects to as a resource is moved. If that resource is referenced in several courses, we only have to update the managed URL in one place to keep all of the links working. It also allows us to easily run link checking on all the links recorded in our managed URL database. Finally, we can collect statistics on the use of the links.
However, there are some problems. It means that an author (or editor) of the learning material can’t just put in a URL – they have to know what the managed URL is for the service – and if one doesn’t already exist, someone has to setup the managed URL before it can be added to the reference.
It also means that the reference example I used above changes into:
JISC Technology Enhanced Learning supporting Students to achieve Academic Rigour (TELSTAR) : JISC, Available from: http://managedurls.open.ac.uk/123456 (Accessed 24 August 2009)
Now, this is still technically correct as a reference and does the job, and within the original context of the reference is probably fine. However, what about if you were to use this reference outside the context of the Open University? Surely using the actual URL for the resource makes more sense (and avoid random traffic via our ‘managed URL’ service coming from use of this reference in non-OU contexts)?
So, it seems desirable that:
- The ‘real’ URL is preserved so that it can be transferred with the reference if it is exported to another context
- The ‘author’ of the reference doesn’t need to know the ‘managed’ URL for the service
- We can manage the link when used within the context of the OU Learning environment
How would we do this?
How about we use the ‘real’ URL as a key to lookup a ‘managed’ URL? So rather than a URL like:
http://managedurls.open.ac.uk/123456
we instead use something like:
http://managedurls.open.ac.uk/www.jisc.ac.uk/whatwedo/programmes/institutionalinnovation/telstar.aspx
We could do this transformation ‘on the fly’, so we wouldn’t need to store the extra information in the reference – we could simply add in the extra information when we display the reference in the learning environment. Any export procedures would simply use the original URL.
Done correctly, if the URL didn’t already exist in our ‘managed’ service, it would simply redirect to the original URL – but at the same time it could alert a member of library staff to the need to add a new managed URL – and apply link checking etc. to it.
One specific method I’ve been pondering is whether we could use an OpenURL construct to push the original URL to a resolver service that would do the work of looking for a ‘managed’ URL. This would look something like:
http://openurl.open.ac.uk/resolver?url_ver=Z39.88-2004&rft_id=http://www.jisc.ac.uk/whatwedo/programmes/institutionalinnovation/telstar.aspx
The OpenURL resolver would need to have access to a database which mapped the URL to whatever the current address of the resource is, but we could make use of existing services like stats collection.
That seems like enough for one post – I’m interested in comments. I’ll come on to linking to other types of resources in subsequent posts.